
Last year we released the Docker Dashboard as part of Docker Desktop, today we are excited to announce we are releasing the next piece of the dashboard to our community customers with a new Images UI. We have expanded the existing UI for your local machine with the ability to interact with your Docker images on Docker Hub and locally. This allows you to: display your local images, manage them (run, inspect, delete) through an intuitive UI without using the CLI. And for you images in Hub you can now view you repos or your teams repos and pull images directly from the UI.
To get started, Download the latest Docker Desktop release and load up the dashboard (we are also excited that we have given the dashboard an icon🎉)
You will be able to see that we have also added a new sidebar to navigate between the two areas and we are planning to add new sections in here soon. To find out more about what’s coming or to give feedback on what you would like to see check out our public roadmap.
Let’s jump in and have a look at what we can do…
From the whale menu, you can access the “Dashboard” and then “Images” where you’ll see a summary and each image with its details: tag, image id, creation date, and size.
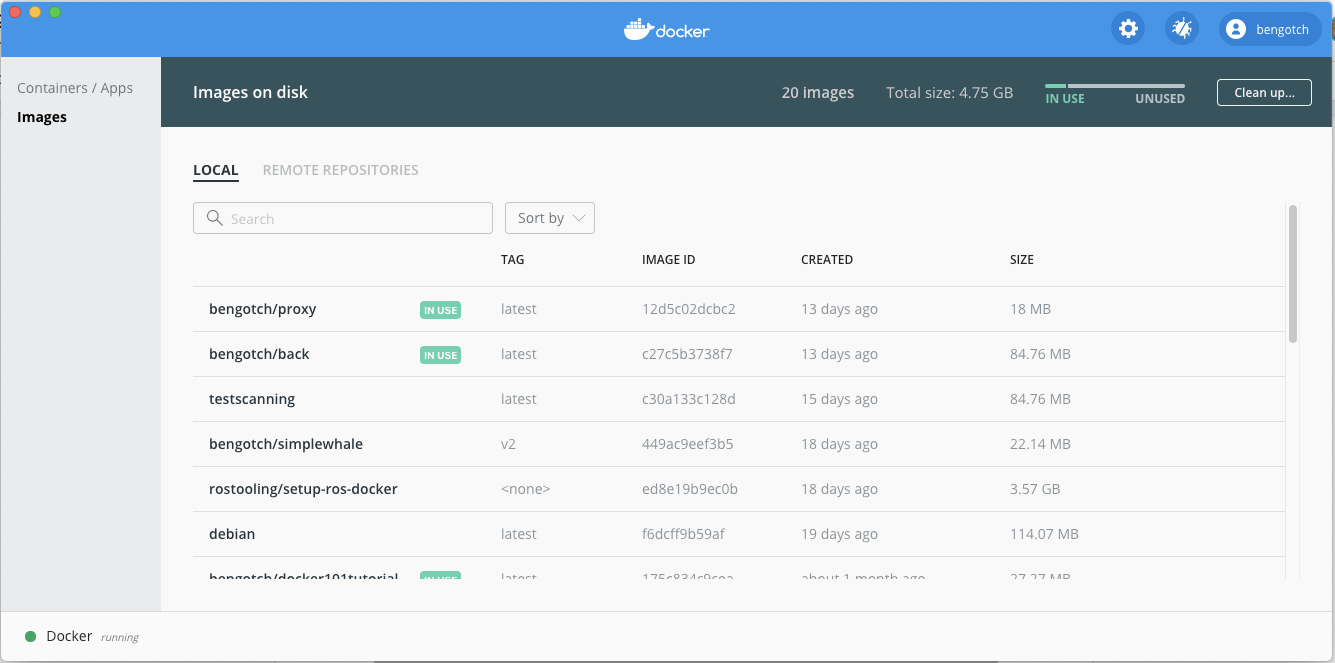
I can also see which of my images are being used by a running or stopped container with 
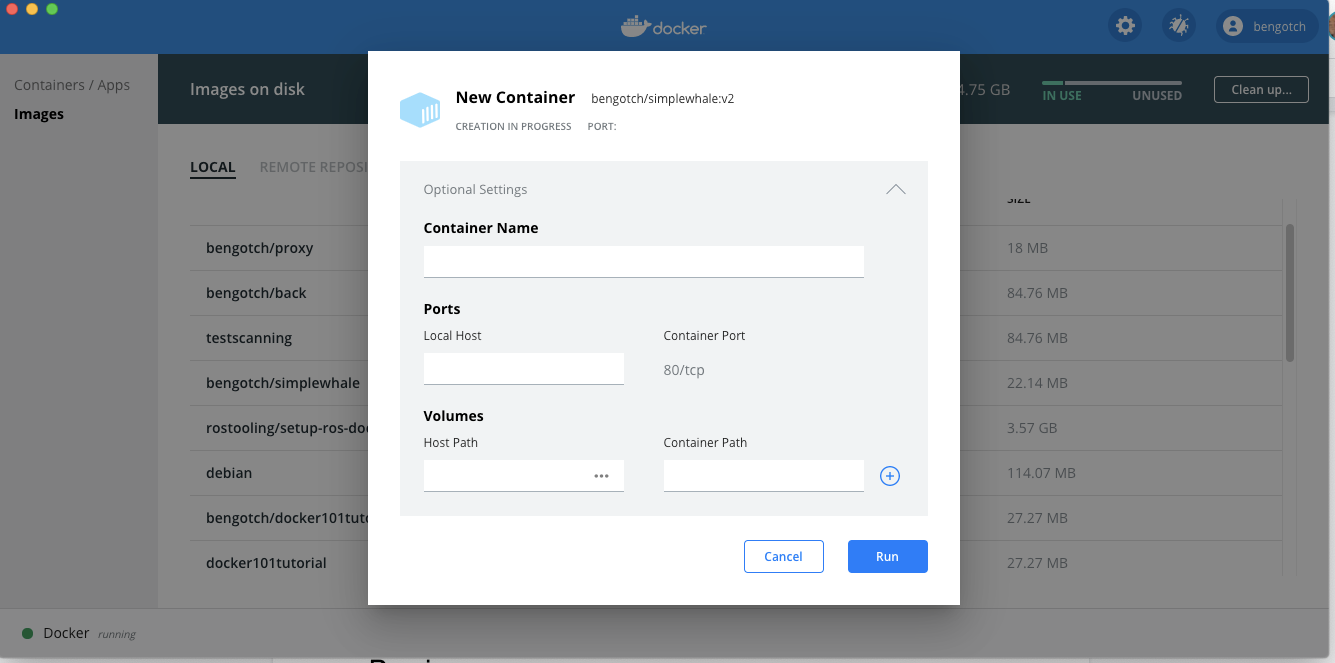
Now I have all these images, I can have a go at running one of them.I will go for my standard demo my simple Whale, when I hover over the image line I can see I get two new buttons, I am going to start off by clicking ‘run’

This pops up a UI where you can either just ‘run’ or add in some values. In this instance I am just going to add a port mapping so I can see what is running in my container once I have started it.
Great this now takes me to my running container UI and I can see that my container is alive!
Next let’s look at clearing up what we have not used so far. I am going to start by hitting the clean up button we saw in the top right corner of our images UI
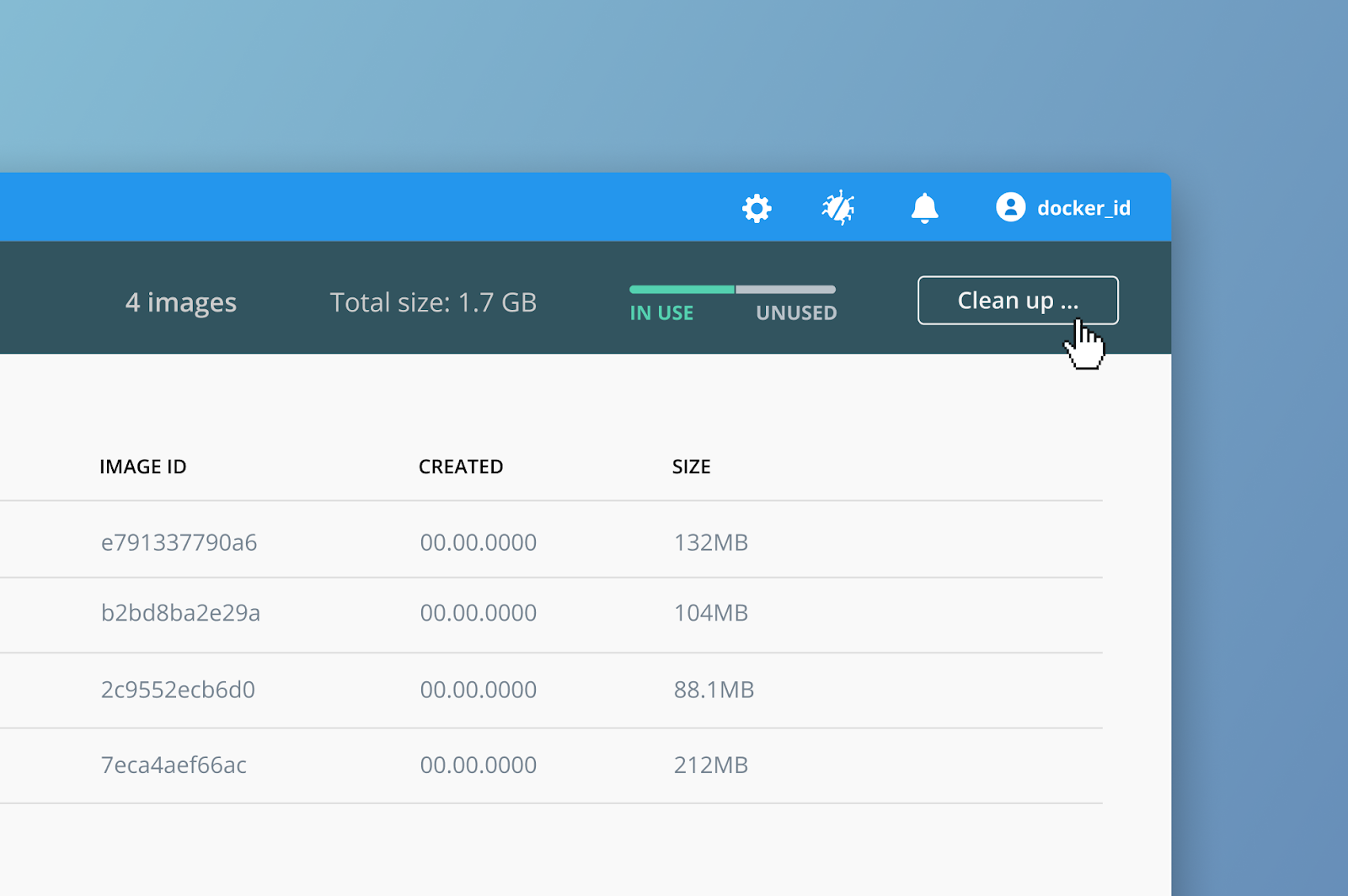
Then my UI changes, I am going to remove all my unused images, I can see I will free up 4gb which isn’t bad!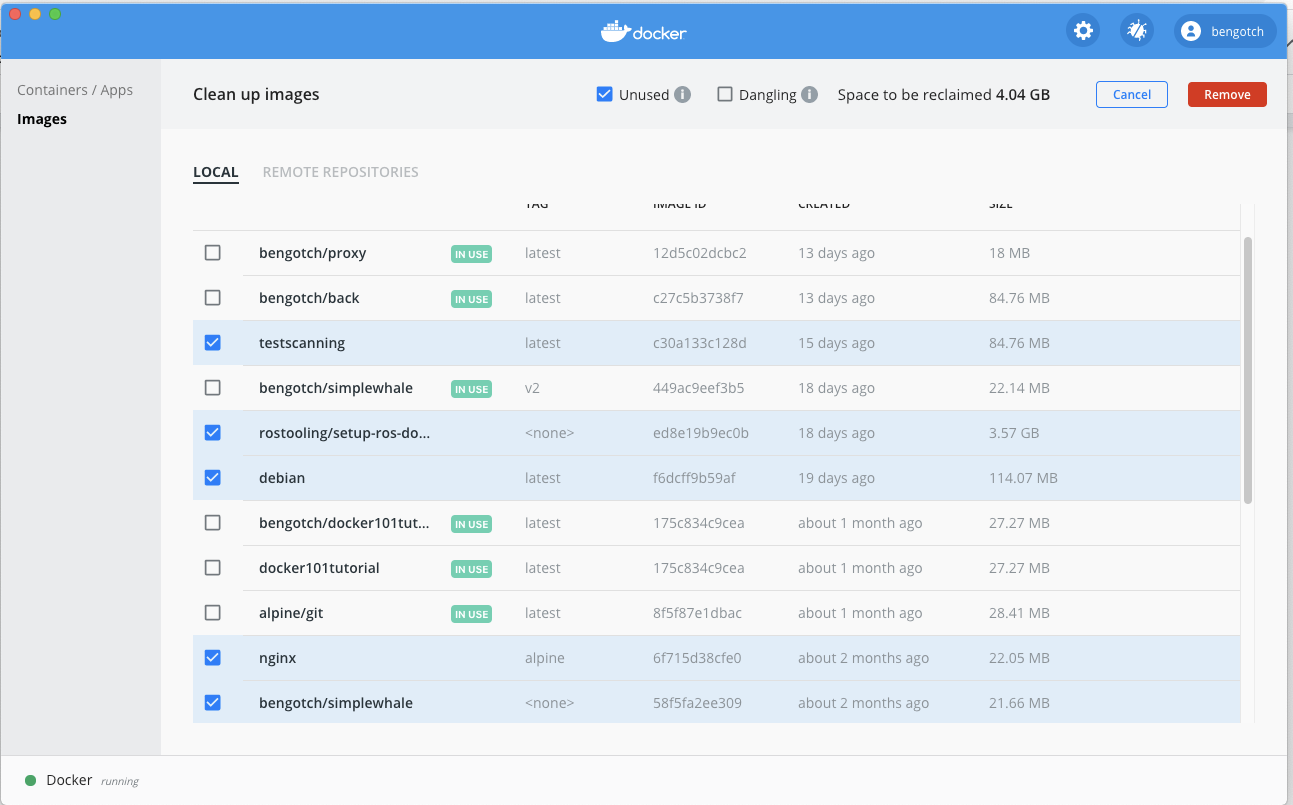
I hit remove up and I can then see after I accept the warning my clean up happens I only have my in use images remaining!

Now let’s have a look at our Hub images, as I am signed in I can just click on the remote repositories tab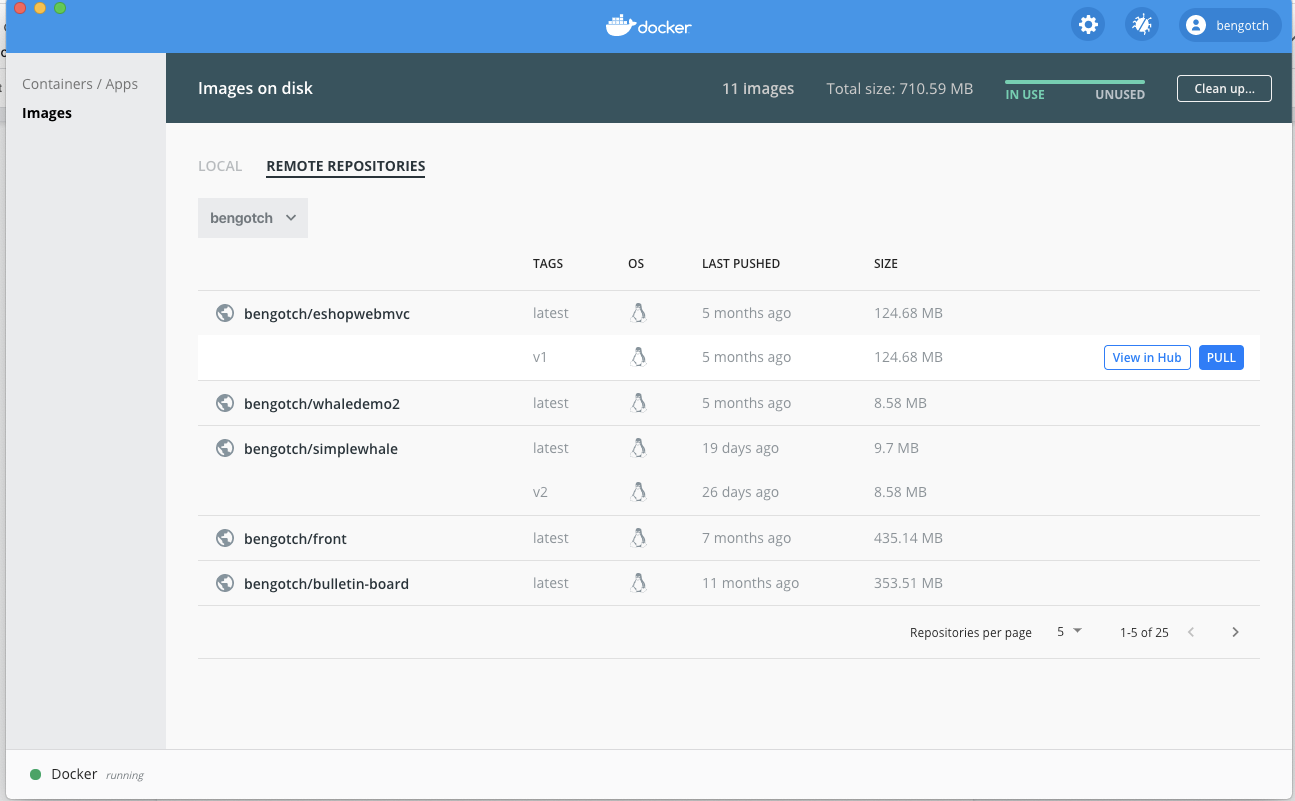
Great! I can now see my repos in Hub along with my tags, I can either pull my image to then run it or I can switch between my Teams to see the repositories in my teams. If I click pull on one of my images, I can see this is started as it takes me back to my local image cache screen and shows me the progress of the download:

I’ve also created an “unboxing” walkthrough of the entire process. You can join me on a guided tour of the new features in this video.
We hope you are as excited as we are for the next piece of our Docker Dashboard, to get started you can download the latest Docker Desktop release to explore your local images. You can try out the Remote Repository functionality by signing into Docker Hub and pulling any of your existing images or if you are new why not try pulling a Docker Official Image like NGINX , retagging it and then having a go at pushing it from the UI.
Feedback
0 thoughts on "The Docker Dashboard Welcomes Hub and Local Images"