
We have heard feedback that given the changes Docker introduced relating to network egress and the number of pulls for free users, that there are questions around the best way to use Docker as part of your development workflow without hitting these limits. This blog post covers best practices that improve your experience and uses a sensible consumption of Docker which will mitigate the risk of hitting these limits and how to increase the limits depending on your use case.
If you are interested in how these limits are addressed in a CI/CD pipeline, please have a look at our post: Best Practices for using Docker Hub for CI/CD. If you are using Github Action, have a look at our Docker Github Actions post.
Prerequisites
To complete this tutorial, you will need the following:
- Free Docker Account
- You can sign-up for a free Docker account and receive free unlimited public repositories
- Docker running locally
- An IDE or text editor to use for editing files. I would recommend VSCode
Determining Number of Pulls
Docker defines pull rate limits as the number of manifest requests to Docker Hub. Rate limits for Docker pulls are based on the account type of the user requesting the image – not the account type of the image’s owner. For anonymous (unauthenticated) users, pull rates are limited based on the individual IP address.
We’ve been getting questions from customers and the community regarding container image layers. We are not counting image layers as part of the pull rate limits. Because we are limiting on manifest requests, the number of layers (blob requests) related to a pull is unlimited at this time
As an anonymous user, you are able to perform up to 100 pulls within a six hour window. This is a high enough limit to allow individual developers to build their images on their local development machine without worry of reaching the pull limits.
If you need to perform more than 100 pulls per six hour window, create a free Docker account which will allow you to perform up to 200 pulls per six hour window. Doubling the amount of pulls compared to the anonymous limit.
To get a good idea of how many pulls a build will incur, you can take a look at the number of FROM commands in your Docker file. Once an image has been pulled to your local machine, it will not incur a pull on subsequent builds.
So for example, if we had an application that was made up of a frontend UI, a REST service and a database. We would have two Dockerfiles. One for building the UI and one for building the REST service. We would then combine these images with our database inside of a compose file. Inside of this compose file, we would include our database image.
Let’s take a look at this scenario using the react-express-mongodb example in the Awesome Compose repository. Clone the awesome-compose repository and open the react-express-mongodb folder in your favorite editor.
$ git clone [email protected]:docker/awesome-compose.git
$ cd awesome-compose/react-express-mongodb
Expand the frontend fold and open the Dockerfile.
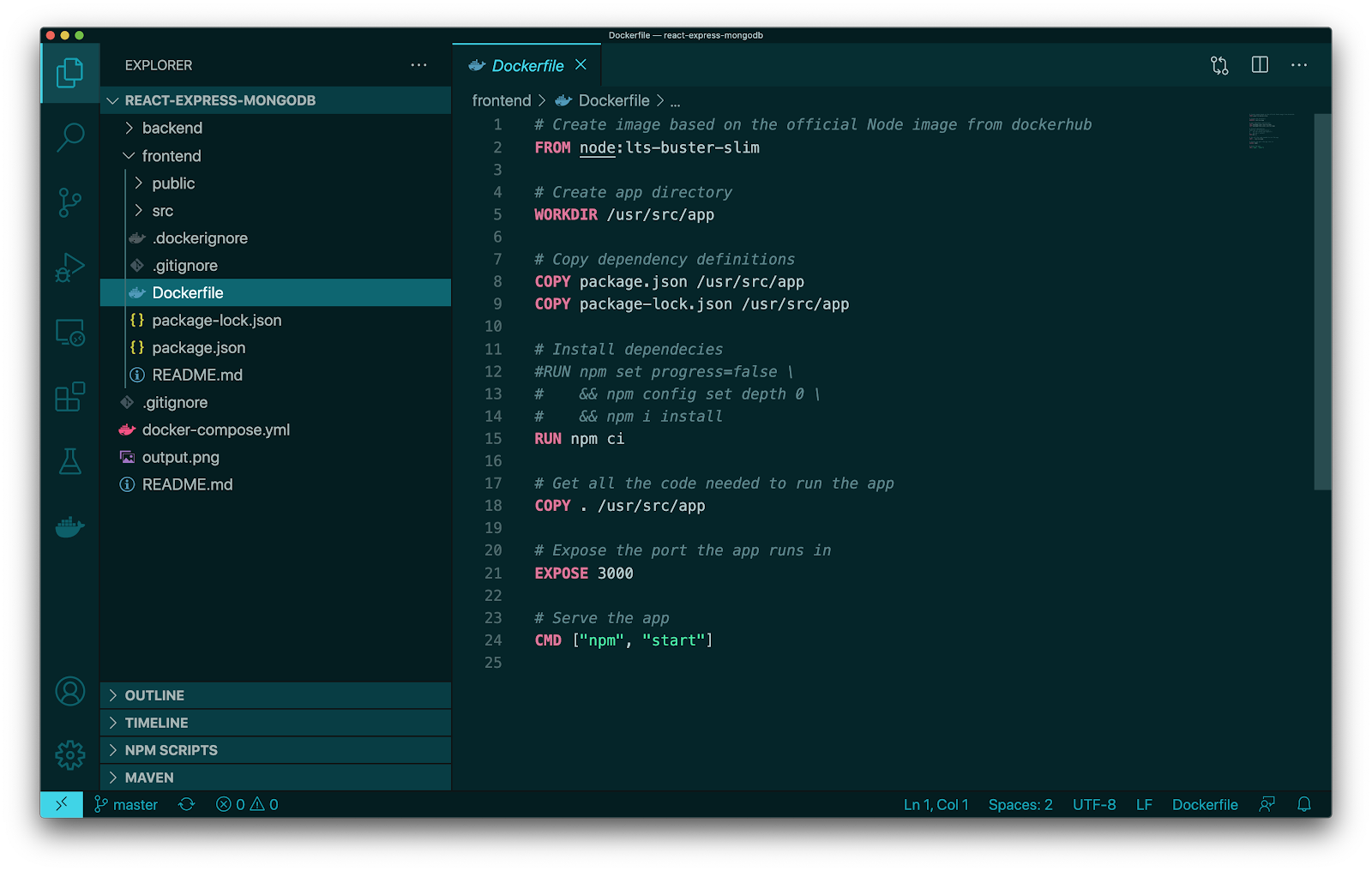
As you can see on line 1, we are using the node:lts-buster-slim image. If we do not already have this image locally then when we perform a build, this image will be pulled from Docker Hub and count as one pull.
Likewise in the backend folder, we see a Dockerfile that is used to build the backend image. On line 1 of this file, we are also using the node:lts-buster-slim image. Again, if you have not already pulled this image from Docker Hub, when you run a docker build, then Docker will pull this image and count it as one pull.
To recap, since we are using the same base image (node:lts-buster-slim) for each of our application images, we will only have to pull that image once and therefore only incur one pull.
The same is true for the mongo:4.2.0 image. When you run the docker-compose up command, the mongo image will be pulled, if not present locally, and increase the pull limit counter by one.
So in the above example, with zero images present locally, you will incur two pull requests to Hub. Even if we expanded this out to a slightly more complex architecture with a few more services that are also written in node, we would still only incur two pull requests. One for the node image and one for the mongodb image.
Now let’s take a look at a more advanced build scenario below.
Here is an example of a Dockerfile that uses multi-stage builds:
1 # syntax=docker/dockerfile:1.1.7
2 ARG GO_VERSION=1.13.7-buster
3
4 FROM golang:${GO_VERSION} AS golang
5
6 FROM golang AS build
7 ....
8 FROM debian:buster AS foo
9 ....
10 FROM scratch AS final
11 COPY --from=build /bin/foo /bin/foo
Simply counting the number of FROM‘s will not work in all situations but it is a good general proxy. If I have a FROM command that references an image that I only have locally, then a Hub pull will not occur. We can also use FROM commands in a multi-stage build to reference other build-stages located in the same Dockerfile.
In the above Dockerfile, we have multiple FROM statements of which the total comprises a multi-stage build. What will actually be pulled from Hub depends on the state of your local cache, which build target is set and whether or not you’re using BuildKit.
Let’s walk through a scenario where we are not using BuildKit.
On line 4 we can see that we are referencing the GO_VERSION build argument:
FROM golang:${GO_VERSION} AS golang
The value of GO_VERSION is dependent on whether we have passed a value using the --build-arg option or not.
So, for example, let’s say we have the golang:1.13.7-buster image on our local machine. If we do not override the GO_VERSION then we will not incur a pull. On the other hand, if we set the GO_VERSION to 1.15.2-buster and do not have this image locally, then we will incur a pull from Hub.
Another point to keep in mind when counting FROMs, is that a FROM command can reference the scratch image. The scratch image is not an image on Hub but is treated specially by Docker and never pulls anything from Hub but is used as a starting point for creating an empty image.
Now let’s take a look at building an image using BuildKit. We’ll use the same sample Dockerfile from above.
When we run a build, the FROM scratch AS final stage is started which will trigger the following flow:
FROM golang AS buildis started- Which triggers the
FROM golang:$(GO_VERSION} AS golangstage - Which will pull the
golang:1.13.7-buster imagefrom Hub if it is not present locally
In this scenario, the FROM debian:buster AS foo stage on line 8 is not used in the final image and therefore will not be built and the debian:buster image will not be pulled from Hub. Even though it is a FROM statement in the Dockerfile, it is not used and need not be counted when figuring out the number of pulls that will occur.
Unlimited Pulls
If you are working on a larger project that has a lot of different base images or you are building images and removing them often, then the best option is to purchase a Docker Pro Account or a Docker Team Account.
Both the Pro and Team accounts give you unlimited pulls and therefore not subject to rate limiting. You also receive unlimited private repositories with these plans.
Conclusion
In this article we discussed how pulls are counted when building images using Docker. We first talked about a common application that has a frontend, backend and a datastore and how this scenario will not reach the 100 pull limit for anonymous users. Then we discussed a more advanced Dockerfile that uses multi-stage builds and how this can potentially affect your pull limits. Although not enough to reach the 200 pull limit for authenticated accounts.
For more information and common questions, please read our FAQ. As always, please feel free to reach out to us on Twitter (@docker) or to me directly (@pmckee).
To get started using Docker sign up for a free Docker account and take a look at our getting started guide.
Feedback
0 thoughts on "Understanding Inner Loop Development and Pull Rates"