
In line with our promise last year to continue publishing incident reviews for Docker Hub, we have two to discuss from April. While many users were unaffected, it is important for us to be transparent with our community, and we hope it is both informative and instructive.
April 3rd 2021
Starting at about 07:30 UTC, a small proportion of registry requests (under 3%) against Docker Hub began failing. Initial investigation pointed towards several causes, including overloaded internal DNS services and significant and unusual load from several users and IPs. Changes were made to address all of these (scaling, blocking, etc), and while the issue seemed to resolve for several hours at a time, it continued coming back.
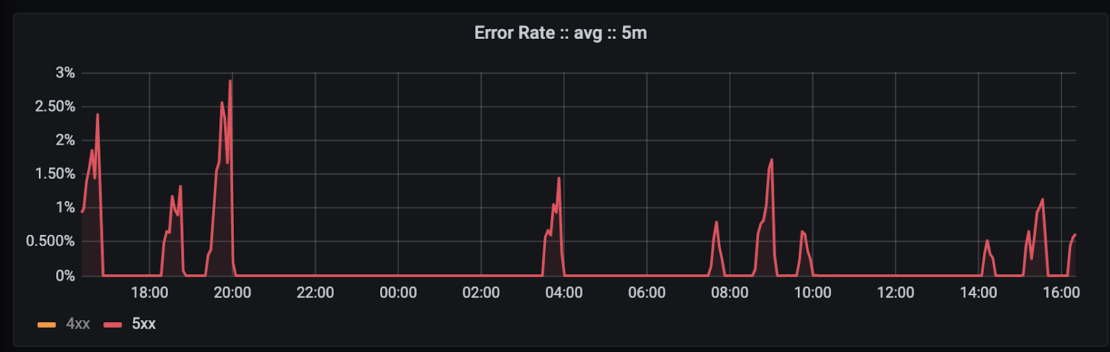
The issue re-occurred intermittently into the next day, at which point the actual root cause was determined to be under-scaled load balancers doing service discovery and routing for our applications.
In the past, the bottleneck for the load balancing system was network bandwidth on the nodes, and auto scaling rules were thus tied to bandwidth metrics. Over time and across some significant changes to this system, the load balancing application had become more CPU intensive, and thus the current auto scaling setup was poorly equipped to handle certain scenarios. Due to the low traffic on the weekend, the system was allowed to scale too low, to the point where CPU became overloaded even though bandwidth was fine. In fact the high CPU load also lead to gaps in metrics reporting from those nodes, which further confirmed the theory:
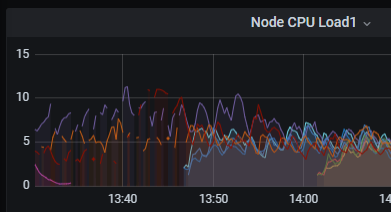
Upon recognizing this, the deployment was manually scaled and the incident resolved at about 20:50 UTC on April 4th.
April 15th 2021
At 17:46 UTC, a change to the registry service was made that scaled up a new version and scaled down an old version. The configuration for our service discovery system needed to be updated to recognize this new version, but the changes were deployed in the wrong order. As such, our load balancers were unaware of any valid backends to serve Docker Hub registry traffic, and registry requests were met with a 503 error response.
The error in deployment was immediately recognized, and the configuration change for service discovery was quickly pushed. The error was resolved by 18:06 UTC.

Learnings and Improvements
With both incidents, we learned that we need more detailed and responsive monitoring for the registry pull request flow. We have already bolstered our internal monitoring to more quickly pick up these scenarios. In addition, while Hub endpoints are monitored externally, they are largely monitored in isolation – for example, checking that the registry API returns a valid response. Work is in progress to more exhaustively test the whole “docker pull” flow involving multiple API calls to multiple services, and from multiple external vantages, which would more quickly pick up on these types of issues.
For the earlier incident, we also made large changes to our load balancing deployment. Autoscaling rules were changed to reflect current bottlenecks (CPU), instance types were changed, and minimum instance counts were set higher. Metrics and alerting were updated to more quickly detect the issue, including looking for gaps in metrics. In the future, load testing for large changes will look at all metrics to determine whether the “bottleneck” attribute has changed.
As always, we take the availability of Docker Hub very seriously. We know millions of developers rely on Hub to get work done and to provide images for production workloads, and as such have made large investments in the reliability of Hub over the past several years. For example, the latter incident was resolved so easily and quickly in part due to better deployment automation built in the last year. We apologize for these incidents, and have taken action to ensure they don’t happen again.
Feedback
0 thoughts on "Docker Hub Incident Reviews – April 3rd and 15th 2021"